Blog AI Text-to-Speech
Some articles in this blog might have text-to-speech (tts) for reading out the articles. By the time anyone is reading this article, I hope I’ve set up the correct pipelines for when I upload a document to automatically generate a tts with my voice from my other machine (it’s very slow by the way). But, since I’ve not done it, because I have not been successful in getting my hands on an NVIDIA Jetson, I really doubt that it will be the case. At least, not anytime soon.
The goal to apply this is really just an excuse for broadening my skills in the AI field. My job requires me to frequently use models for computer vision (ones that would work well on edge computers), so I’m really quite familiar for applying AI in the image processing scene. I’ve also taken a few classes on natural language processing, and learned quite a bit about LLMs. Though at that time, BERT was the model that I frequently heard about. Now, it’s all about GPT models. So, I’m slightly familiar with the application of AI in the text or natural language scene. This The one field that I really have no knowledge on is the application of AI on speech or voice. It wasn’t a class that I was interested in when I was in college, partly because my friend told me that it was quite hard to get a decent score on that class. But when I was building this website and was thinking of what I could add more, I thought an ai model with my voice reading articles that I’ve written could be a fun idea. I’ll also get to learn more about some stuff that I know nothing about. And who knows, maybe it could be something that’s really interesting. The other reason is also when watching some of my favorite twitch streamers, I noticed that lately the text-to-speech they’re using was quite convincing when it’s imitating voices of really prominent figures. I was quite interested by the idea of some famous person reading my articles, but thought that wouldn’t be morally right, so I chose to just use my voice instead. So, I went to search for some ai models that could fit my use case.
The Search
I spent a few days looking for a github repository that I could use while learning about this new field and found a couple of repositories that interested me. One very popular repository is the real-time-voice-cloning repository by CorentinJ. But, I noticed that the repository has gotten quite stale as it has not seen any updates in the past few years. But that repository gave me a lead to something that I use, which is coqui-ai’s TTS repository. I started to learn how to get it up and running. Getting it up and running is surprisingly, quite a pain. A lot of conflicting packages with my pyenv configuration which put doubts in my mind on using pyenv in the future to manage my python installations and packages. But alas, I got it up and running and recorded some voice lines and successfully generated some speech! And the result was… quite disappointing really. The speech generated does not sound at all like me and it was very slow to get any result (I’m running it on my OrangePi 5 w/ mali GPU). I learned the hard way that it’s really quite hard to create a decent speech model. I also learned the hard way that the money I spent on my OrangePi 5 does not mean anything at all. It’s a pain to try to figure out how to use the mali GPU that was in the machine to get some form of hardware acceleration when running my AI model, and in the end it didn’t work at all. I thought there would be some experimental modules in tensorflow or pytorch that would allow me to use the GPU that was in my machine, but there’s really nothing at all. When searching on the internet, I only found other people who were asking the same questions as I was. I really should’ve just bought some machine with an NVIDIA GPU from the start… I decided to not use coqui-ai’s TTS and started to look for better and faster alternatives. I also found out that coqui-ai was shutting down (or sold?) and thought it would just be better if I switch anyway. Not sure how that would affect anything in my pipeline if the repository just went stale after this, but I wanted something else that I could use. That lead me to OpenVoice.
OpenVoice
I cloned the OpenVoice repository and set up the python environment (which still was quite a pain) and got it up and running. The repository was really helpful for basically guiding me through every steps to get it working since it has a few ipynb files that I could read through to synthesize speech. I chose a base speaker from MeloTTS, wrote some mock articles, and ran the model to create the audio file. The result… is similarly disappointing. I had already re-recorded some voice lines because I thought my voice lines just weren’t good. I downloaded Audacity just for this and processed my voice, removed background noises and everything, and the result was still quite far from ideal. And the worst part is that it was still really slow when running it on my orange pi. I really thought if the voice weren’t good, at least I need a machine that could run it faster to experiment more. But experimenting more was just not feasible since it was really testing my patience just to get a few lines synthesized. But this is quite far from done, I’m planning to get my hands on some NVIDIA Jetsons, maybe by the end of the year so I can experiment more later. My conclusion is that if I wanted a model with a good representation of my voice, the only option was to train or fine-tune the already existing models with my voice as data. However, learning about preprocessing speech data and recording the training data just sounds like a pain for now, so I’ve decided that it’s something that I will be doing later (just like any of my other projects). For now, people who listen to the articles I’ve written just have to deal with a broken voice that sounds nothing similar to me. Or I might just use some random voice that MeloTTS provided already in their base speakers and not clone any voice… Or the more realistic option, I might just use another method or a specialized service to synthesize speech for my articles… Instant voice cloning might not be the appropriate method to achieve my goal of having my voice read my articles. It seems to be just fine when using short voice lines from popular video game characters, to synthesize more short voice lines. But it seems to struggle generating whole articles from my the short lines I recorded on my terrible microphone, or maybe my voice is just not suitable with the base speakers that were provided.
The Model Details
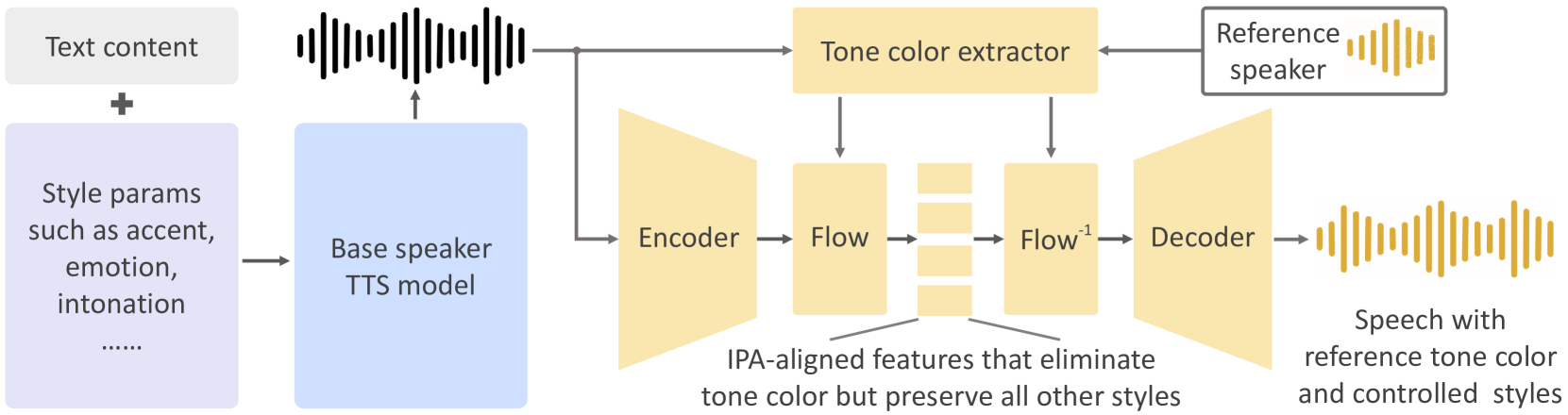
The above is the illustration of the OpenVoice framework for voice cloning and speech synthesizing. The gist of it is that it uses other base speaker text-to-speech models and a reference speaker’s voice. In my case, the base speaker model is ones provided from MeloTTS. There is also a tone color converter to represent the reference speaker’s unique features, given the reference audio file. The tone color converter itself is an encoder-decoder, which might be familiar to some people if they know about cloning art styles in some generative models. They also might use an encoder-decoder based approach to first embed the style in latent space and then try to recreate the input when trained. And then they can use the trained encoder-decoder to input other images and recreat the image in some other art styles. The tone color extractor is a 2D convolutional neural network that operates on the reference speaker input to generate a single feature vector that represents the tone color informations. This extracted tone color information is used within the encoder-decoder to synthesize speech.
The tone color itself is something that I struggled with when first learning about it, I just couldn’t quite understand what it actually represents because I’m not quite familiar with speech data. What I’ve gathered and concluded is that it’s the personality of someone’s voice encoded in some numbers or weight that represents not just the pitch of someone’s voice, but also the flow of how someone talks. I’m sure there’s a lot more to what actually goes into representing someone’s voice, but that’s kind of what I’ve gathered from recording multiple voice lines and trying to make some voices with my actual voice.
The capabilities of the OpenVoice model is actually quite surprising, it boasts about zero-shot learning that enables the reference voice not to be in the same language as the desired output language. This is something that I’ve tried and the results were quite consistent. Sure, the voice is the same similar broken representation of my voice, but it was quite the same for the languages I’ve tested. All in all, I think learning about this just makes me interested more in cloning my voice, getting an actual good representation of my voice in a model that I can use not just for reading my articles, but maybe for other projects.
Footnote
I’ve always quite struggled when listening to recordings of my voice before this. I didn’t like my voice before, and would just opt out of listening to old recordings of me speaking. But after listening to the synthesized voice of this model, I think my voice is actually not that bad. I’ll be sure to improve this project later on and make it actually work as my intended goal.
My goal now is to get a machine that I can efficiently use to experiment with AI. Because I would really like to not spend over 5 minutes just to synthesize a text that would’ve taken me 1 minute to read.
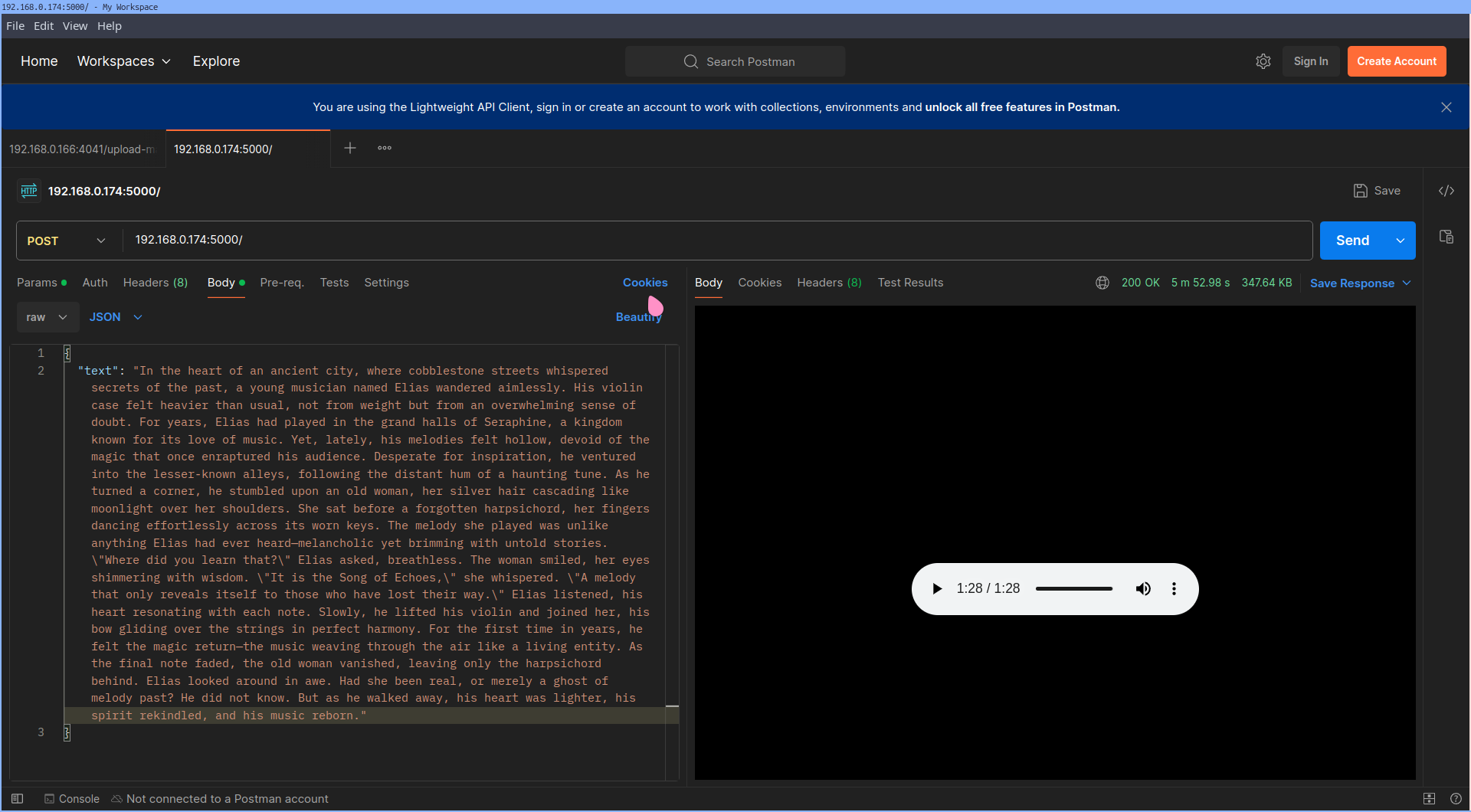
Just look at that atrocious inference time, reading that text would not take me longer than 5 minutes! Sure, it woud take some time to boot up Audacity and remove background noise after recording, but I think that’s just unacceptable if I want to implement it in my current pipeline.
The most important thing I’ve come to learn is this new field that I’m now slightly interested in and also learning to sit with my voice and being okay with it.